

5장 웹서버
5. 1 웹 서버가 하는 일
- 커넥션을 맺는다. 클라이언트의 접속을 받아들이거나, 원치 않는 클라이언트라면 닫는다.
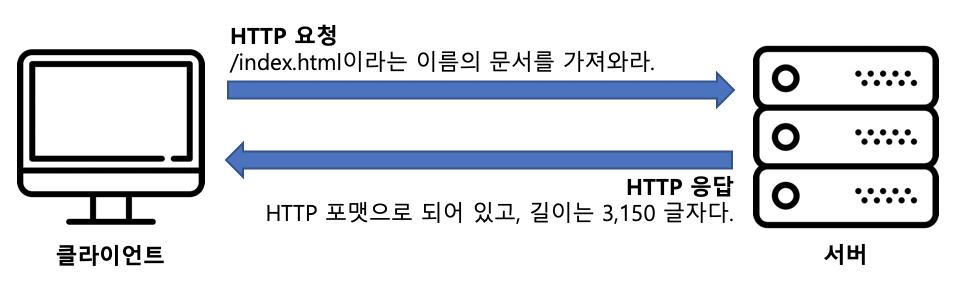
- 요청을 받는다. HTTP 요청 메시지를 네트워크로부터 읽어드린다.
- 요청을 처리한다. 요청 메시지를 해석하고 행동을 취한다.
- 리소스에 접근한다. 메시지에서 지정한 리소스에 접근한다.
- 응답을 만든다. 올바른 헤더를 포함한 HTTP 응답 메시지를 생성한다.
- 응답을 보낸다. 응답을 클라이언트에게 돌려준다.
- 트랜잭션을 로그로 남긴다. 로그 파일에 트랜잭션 완료에 대한 기록을 남긴다.
5.2 단계 1: 클라이언트 커넥션 수락
클라이언트가 이미 서버에 대해 열려있는 지속적 커넥션을 갖고 있다면, 클라이언트는 요청을 보내기 위해 그 커넥션을 사용할 수 있다.
5.2.1 새 커넥션 다루기
- 클라이언트가 웹서버에 TCP 커넥션 요청을 하면, 웹 서버는 커넥션을 맺고 IP 주소를 추출하여 어떤 클라이언트가 있는지 확인한다.
- 서버는 새 커넥션을 커넥션 목록에 추가하고 커넥션에서 오가는 데이터를 지켜보기 위한 준비를 한다.
- 웹 서버는 어떤 커넥션이든 마음대로 거절하거나 즉시 닫을 수 있다.
5.2.2 클라이언트 호스트 명 식별
- 웹 서버는
역방향 DNS를 사용해서 클라이언트의 IP 주소를 호스트명으로 변환하도록 설정되어 있다. - 호스트 명 룩업은 꽤 시간이 많이 걸릴 수 있어 웹 트랜잭션을 느려지게 할 수 있다.
5.2.3 ident를 통해 클라이언트 사용자 알아내기
- ident 프로토콜은 서버에게 어떤 사용자 이름이 HTTP 커넥션을 초기화 했는지 찾아낼 수 있게 한다.
- 웹 서버 로깅에서 유용하여, 일반 로그 포맷의 두 번째 필드는 각 HTTP 요청의 사용자 이름을 담는다.
5.3 단계 2: 요청 메시지 수신
커넥션에 데이터가 도착하면, 웹 서버는 네트워크 커넥션에서 그 데이터를 읽어 들이고 파싱하여 요청 메시지를 구성한다.
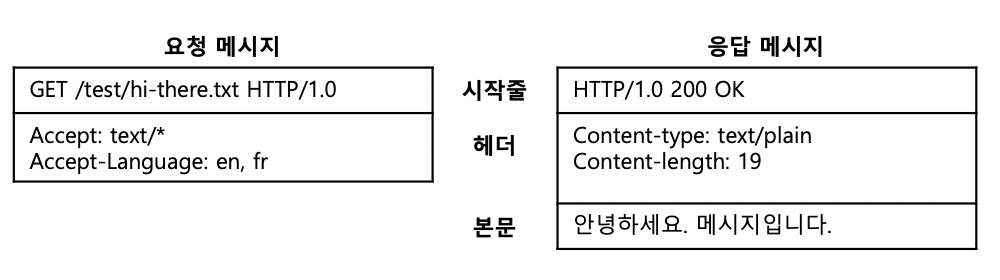
- 요청줄을 파싱하여 요청 메서드, 지정된 리소스의 식별자, 버전 번호를 찾는다.
- 메시지 헤더들을 읽는다. 각 메시지 헤더는 CRLF로 끝난다.
- 헤더의 끝을 의미하는 CRLF로 끝나는 빈 줄을 찾아낸다.
- 요청 본문이 있다면, 읽어 들인다.
5.3.1 메시지의 내부 표현
웹 서버는 요청 메시지를 쉽게 다룰 수 있도록 내부의 자료 구조에 저장한다.
5.3.2 커넥션 입력/출력 처리 아키텍쳐
- 웹 서버는 수천 개의 커넥션을 동시에 열 수 있도록 지원한다.
- 커넥션들은 웹 서버가 전 세계의 클라이언트들과 각각 한 개 이상의 커넥션을 통해 통신할 수 있게 해준다.
- 웹 서버 아키텍쳐의 차이에 따라 요청을 처리하는 방식도 달라진다.
단일 스레드 웹 서버
- 한 번에 하나씩 요청을 처리한다.
- 트랜잭션이 완료되면, 다음 커넥션이 처리된다.
- 처리 도중에 모든 다른 커넥션은 무시된다.
멀티프로세스와 멀티스레드 웹 서버
- 웹 서버는 요청을 동시에 처리하기 위해 여러 개의 프로세스 혹은 고효율 스레드를 할당한다.
- 커넥션을 처리 할 때 만들어진 수많은 프로세스나 스레드는 많은 메모리나 시스템 리소스를 소비한다.
- 많은 멀티스레드 웹 서비스가 스레드/프로세스의 최대 개수에 제한을 건다.
다중 I/O 서버
- 커넥션의 상태가 바뀌면, 그 커넥션에 대한 작은 양의처리가 수행된다.
- 그 처리가 완료되면, 커넥션은 다음 상태 변경을 위해 열린 커넥션 목록으로 돌아간다.
- 스레드와 프로세스는 유휴 상태의 커넥션에 얽혀 기다리느라 리소스를 낭비하지 않는다.
다중 멀티스레드 웹서버
- CPU 여러 개의 이점을 살리기 위해 멀티스레딩과 다중화를 결합한다.
- 여러 개의 스레드는 각각 열려있는 커넥션을 감시하고 각 커넥션에 대해 조금씩 작업을 수행한다.
5.4 단계 3: 요청 처리
웹 서버가 요청을 받으면, 서버는 요청으로부터 메서드, 리소스, 헤더, 본문을 얻어내어 처리한다.
5.5 단계 4: 리소스의 매핑과 접근
웹 서버는 리소스 서버다. 클라이언트가 웹 서버에 리소스를 요청하면, 웹 서버는 요청 메시지의 URI에 대응하는 알맞는 콘텐츠나 콘텐츠 생성기를 찾아서 클라이언트로 전달한다.
5.5.1 Docroot
- 리소스 매핑을 하는데 요청 URI를 웹 서버의 파일 시스템 안에 있는 파일 이름으로 사용하는 것이 가장 쉽다.
- 일반적으로 웹 서버 파일 시스템의 특별한 폴더를 웹 콘텐츠를 위해 예약해 둔다.
- 이 폴더는
문서 루트혹은docroot로 불린다.
가상 호스팅된 docroot
- 각 사이트에 그들만의 분리된 문서 루트를 주는 방법이다.
- 하나의 웹 서버 위에서 두 개의 사이트가 완전히 분리된 콘텐츠를 갖고 호스팅 되도록 할 수 있다.
사용자 홈 디렉터리 docroots
- 사용자들이 한 대의 웹 서버에서 각자의 개인 웹사이트를 만들 수 있도록 해주는 것이다.
- 보통 사용자 이름이 오는 것으로 시작하는 URI는 그 사용자의 개인 문서 루트를 가리킨다.
GET /~jeus/index.html HTTP/1.0
5.5.2 디렉터리 목록
- 웹 서버는 경로가 파일이 아닌 디렉터리 URL에 대한 요청을 받을 수 있다.
- 사용자가 어떤 디렉터리에 대한 URL을 요청했는데, 그 디렉터리가
index.html이란 이름을 가진 파일을 갖고 있다면, 서버는 그 파일의 콘텐츠를 반환한다. - 웹 서버는 기본 디렉터리 파일로 사용될 파일 이름의 집합인
DirectoryIndex지시자를 사용해서 색인 파일로 사용될 모든 파일의 이름을 우선순위로 나열한다.
5.5.3 동적 콘텐츠 리소스 매핑
- 웹 서버는 URI를 동적 리소스에 매핑할 수 있다.
- 애플리케이션 서버라고 불리는 것들은 웹 서버를 복잡한 백엔드 애플리케이션과 연결하는 일을 한다.
5.5.4 서버사이드 인클루드(Server-Side Includes, SSI)
- 어떤 리소스가 서버사이드 인클루드를 포함하고 있다면, 서버는 그 리소스의 콘텐츠를 클라이언트에게 보내기 전에 처리한다.
- 서버는 콘텐츠에 변수 이름이나 내장된 스크립트가 될 수 있는 어떤 특별한 패턴이 있는지 검사를 받는다.
5.5.5 접근제어
- 접근제어 되는 리소스에 대한 요청이 도착했을 때 웹 서버는 클라이언트의 IP주소에 근거하여 접근을 제어할 수 있고 혹은 리소스에 접근하기 위한 비밀번호를 물어볼 수 있다.
5.6 단계 5: 응답 만들기
5.6.1 응답 엔터티
만약 트랜잭션이 응답 본문을 생성한다면, 그 내용을 응답 메시지와 함께 돌려보낸다.
- 응답 본문의 MIME 타입을 서술하는 Content-Type 헤더
- 응답 본문의 길이를 서술하는 Content-Length 헤더
- 실제 응답 본문의 내용
5.6.2 MIME 타입 결정하기
mime.types
- 웹 서버는 각 리소스의 MIME 타입을 계산하기 위해 확장자별 MIME 타입이 담겨 잇는 파일을 탐색한다.
매직 타이핑
- 웹 서버는 각 파일의 MIME 타입을 알아내기 위해 파일의 내용을 검사해서 알려진 패턴에 대한 테이블에 해당하는 패턴이 있는지 찾아 볼 수 있다.
유형 명시
- 특정 파일이나 디렉터리 안의 파일들이 파일 확장자나 내용에 상관없이 어떤 MIME 타입을 갖도록 웹 서버를 설정할 수 있다.
유형 협상(Type negotiation)
- 웹 서버는 한 리소스가 여러 종류의 문서 형식에 속하도록 설정할 수 있다.
5.6.3 리다이렉션
- 웹 서버는 요청을 수행하기 위해 브라우저가 다른 곳으로 가도록 리다이렉트 할 수 있다.
- 리다이렉션 응답은
3XX상태코드로 지칭된다.
영구히 리소스가 옮겨진 경우
- 리소스는 새 URL이 부여되어 새로운 위치로 옮겨졌거나 이름이 바뀔 수 있다.
- 웹 서버는 클라이언트에게 리소스 위치가 변경되었음을 알려준다.
301 Moved Permanently상태 코드가 사용된다.
임시로 리소스가 옮겨진 경우
- 리소스가 임시로 옮겨지거나 이름이 변경되었지만, 서버는 클라이언트가 나중에는 원래 URL로 찾아오고 북마크도 갱신하길 원치 않는다.
303 See Ohter와307 Temporary Redirect상태 코드가 사용된다.
URL 증강
- 서버는 종종 문맥 정보를 포함ㅎ시키기 위해 재 작성된 URL로 리다이렉트한다.
- 요청이 도착했을 때, 서버는 상태 정보를 내포한 새 URL을 생성하고 사용자를 이 새 URL로 리다이렉트한다.
- 클라이언트는 상태정보가 추가된 완전한 URL을 포함한 요청을 다시 보낸다.
303 See Ohter와307 Temporary Redirect상태 코드가 사용된다.
부하 균형
- 서버가 과부화된 요청을 받으면, 서버는 클라이언트를 덜 부하가 걸린 서버로 리다이렉트 할 수 있다.
303 See Ohter와307 Temporary Redirect상태 코드가 사용된다.
친밀한 다른 서버가 있을때
- 서버는 클라이언트에 대한 정보를 갖고 있는 다른 서버로 리다이렉트 할 수 있다.
303 See Ohter와307 Temporary Redirect상태 코드가 사용된다.
디렉터리 이름 정규화
- 클라이언트가 디렉터리 이름에 대한 URI를 요청하는데
/을 빠뜨렸다면, 웹 서버는/를 추가한 URI로 리다이렉트한다.
5.7 단계 6: 응답 보내기
- 서버는 여러 클라이언트에 대한 많은 커넥션을 가질 수 있다. 서버는 커넥션 상태를 추적해야 하며 지속적인 커넥션은 특별히 주의해서 다룰 필요가 있다.
- 비지속적인 커넥션이라면, 서버는 모든 메시지를 전송했을 때 자신쪽의 커넥션을 닫을 것이다.
- 지속적인 커넥션이라면, 서버가 Content-length 헤더를 바르게 계산하기 위해 특별한 주의를 필요로 하는 경우나, 클라이언트가 응답이 언제 끝나는지 알 수 없는 경우에, 커넥션은 열린 상태를 유지한다.
5.8 단계 7: 로깅
트랜잭션이 완료 되었을 때 웹 서버는 트랜잭션이 어떻게 수행되었는지에 대한 로그를 로그파일에 기록한다.