



13장 다이제스트 인증
목표: 기본 인증과 호환되는 더 안전한 대체재로서의 다이제스트 인증을 알아본다.
1. 다이제스트 인증의 개선점
특징
- 비밀번호를 절대로 네트워크를 통해 평문으로 전송하지 않는다.
- 인증 체결을 가로채서 재현하려는 악의적인 사람들을 처단한다.
- 구현하기에 따라서, 메시지 내용 위조를 막는것이 가능하다.
- 그 외의 잘 알려진 형태의 공격을 막는다.
1.1 비밀번호를 안전하게 지키기 위해 요약 사용하기
- 다이제스트 인증을 요약하면 “절대로 비밀번호를 네트워크를 통해 보내지 않는다” 이다.
- 클라이언트는 비밀번호를 비가역적으로 뒤섞은
지문(fingerprint)혹은요약(digest)를 보낸다.
1.2 단방향 요약
요약은 ‘정보 본문의 압축’이다.- 요약은 단방향 함수로 동작하고, 무한 가지의 모든 입력 값들을 유한한 범위의 압축으로 변환한다.
- 만약 비밀번호를 모른다면 서버에게 보내줄 알맞은 요약을 추측하기 위해 많은 시간을 소모하게 된다.
- 요약은 비밀번호를 그대로 전송해야 할 필요성에서 해방시켜준다.
1.3 재전송 방지를 위한 난스(nonce) 사용
요약은 비밀번호 자체와 다름 없으므로 요약을 가로챈다면 요약을 서버로 재전송할 수 있다.- 재전송을 막기 위해서 서버는 클라이언트에게
난스라고 불리는 특별한 증표를 넘겨준다. - 난스는 약 1밀리초마다, 인증할때마다 바뀌게 된다.
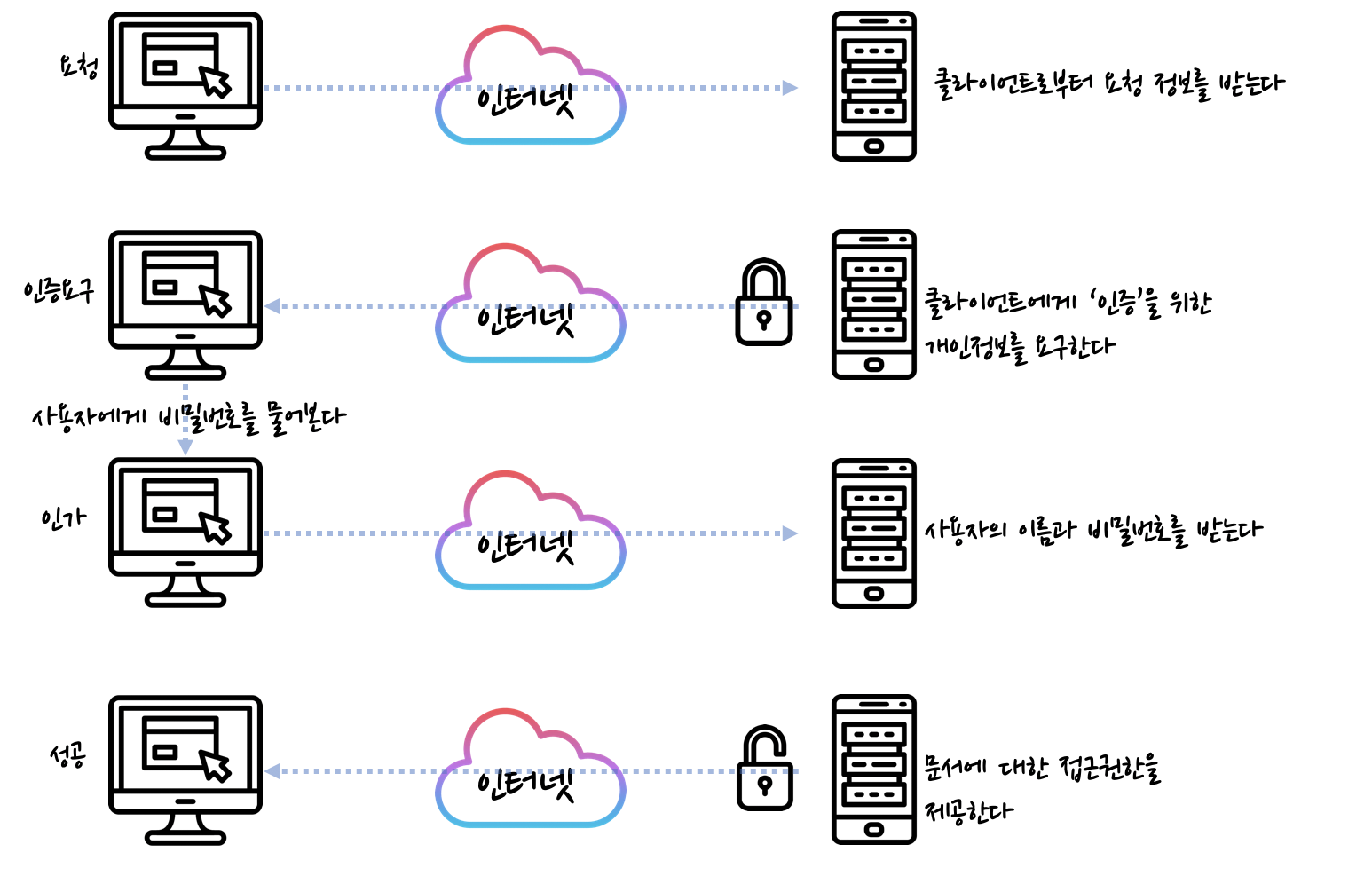
1.4 다이제스트 인증 핸드 셰이크
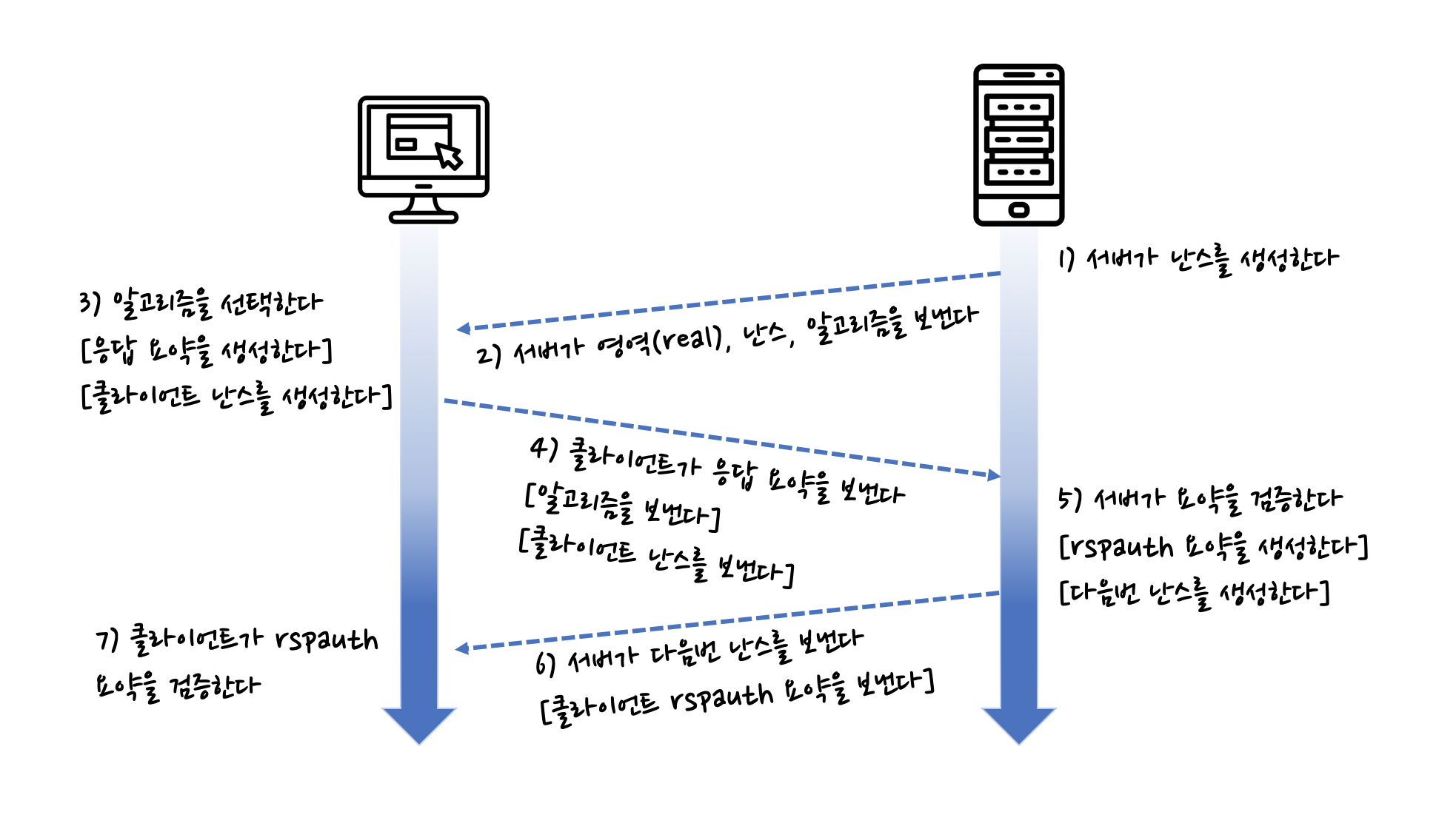
- 서버는 난스 값을 계산한다.
- 서버는 난스를 WWW-Authenticate 인증요구 메시지에 담아, 알고리즘 목록과 함께 클라이언트에 보낸다.
- 클라이언트는 알고리즘을 선택하고 비밀번호와 그 외 데이터에 대한 요약을 계산한다.
- 클라이언트는 Authorization 메시지에 요약을 담아 서버에게 돌려준다.
- 서버는 요약, 선택한 알고리즘, 그 외 보조 데이터들을 받고, 클라이언트가 했던 그대로 요약을 계산한다. 서버는 자신이 계산한 요약과 네트워크로 전송되어 온 요약이 서로 같은지 확인한다.
2. 보호 수준(Quality of Protection) 향상
- qop 필드는 클라이언트와 서버가 어떤 보호 기법을 어느 정도 수준으로 사용할 것인지 협상할 수 있게 해준다.
2.1 메시지 무결성 보호
- 무결성 보호가 적용되었을 때 계산되는 엔터티 본문은, 메시지 본문의 해시가 아닌 엔터티 본문의 해시이다.
- 송신자에 의해 어떠한 전송 인코딩이 적용되기도 전에 먼저 계산되고 그 후 수신자에 의해 제거된다.
2.2 다이제스트 인증 헤더
- 기본, 다이제스트 인증은 WWW-Authentication 헤더에 담겨 전달되는 인증요구와, Authentication 헤더에 담겨 전달되는 인기 응답을 포함한다.
- 다이제스트는 Authentication-Info 헤더를 추가했다.
- 3단계 핸드셰이크를 완성하고 다음번 사용할 난스를 전달하기 위해 인증 성공 후에 전송된다.
3. 다이제스트 인증 작업시 고려할것들
3.1 다중 인증요구
- 서버는 한 리소스에 대해 여러 인증을 요구할 수 있다.
- 다양한 인증 옵션을 제공하는 경우, ‘
가장 허약한 부분‘에 대한 보안우려가 있다는 것이 명확하다.
3.2 오류처리
- 지시자나 그 값이 적절하지 않거나 요구된 지시자가 빠져 있으면, 응답은 400 Bad Request이다.
- 인증 서버는
uri지시자가 가리키는 리소스가 요청줄에 명시된 리소스와 같음을 확인해야 한다. - 반복된 실패에 대해서는 따로 기록해 두는 것이 좋다.
3.3 보호 공간(Protection Space)
영역 값은 접근한 서버의 루트 URL과 결합되어 보호 공간을 정의한다.- 영역 값은 원 서버에 의해 할당되는 문자열이며 인증 제도에 추가적인 의미를 더한다.
- 보호 공간은 어떤 자격이 자동으로 적용되는 영역을 정한다.
3.4 URI 다시 쓰기
- 프락시는 가리키는 리소스의 변경 없이 구문만 고쳐서 URI를 다시 쓰기도 한다.
- 호스트 명은 정규화되거나 IP 주소로 대체된다.
- 문자들은
%escape 형식으로 대체될 수 있다. - 서버로부터 가져오는 리소스에 영향을 주지 않는, 타입에 대한 추가 속성이 URI의 끝에 붙거나 중간에 삽입될 수 있다.
3.5 캐시
Authorization 헤더를 포함한 요청과 그에 대한 응답을 받은 경우, 두 Cache-Control 지시자 중 하나가 응답에 존재하지 않는 한 다른 요청에 대해 응답을 반환해서는 안된다.
4. 보안에 대한 고려사항
4.1 헤더 부당 변경
헤더 부당 변경에 대해 안전한 시스템을 제공하기 위해서, 양 종단 암호화나 헤더에 대한 디지털 서명이 필요하다.
4.2 재전송 공격
- 폼 데이터를 전송할 때 이전에 사용했던 자격을 재사용해도 문제없이 동작한다면, 큰 문제가 생기게 된다.
- 재전송 공격을 완전히 피하기 위해서는 매 트랜잭션마다 유일한 난스 값을 사용하는 것이다.
- 서버는 매 트랜잭션마다
난스와 함께타임아웃값을 발급한다.
4.3 다중 인증 메커니즘
- 클라이언트에게 항상 가장 강력한 인증제도를 선택하도록 한다.
- 가장 강력한 인증 제도만을 유지하는 프락시 서버를 사용한다.
4.4 사전 공격
- 전형적인 비밀번호 추측 공격이다.
- 비밀번호 만료 정책이 없고, 충분한 시간이 있고, 비밀번호를 크래킹할 비용을 치를 수 있다면, 비밀번호를 쉽게 수집할 수 있다.
- 크래킹하기 어렵도록 복잡한 비밀번호를 사용하고 괜찮은 비밀번호 만료 정책을 사용하는 것이 좋다.
4.5 악의적인 프락시와 중간자 공격
- 프락시중 하나가 악의적이거나 보안이 허술하다면 클라이언트는 중간자 공격에 취약한 상태가 될 수 있다.
- 프락시는 보통 정교한 프로그래밍 인터페이스를 제공하므로 그러한 프락시들을 이용하는 플러그인을 이용하여 트래픽을 가로채 수정하는 것이 가능하다.
- 이 문제를 해결하기에는 한계가 있으므로, 클라이언트가 가능한 가장 강력한 인증을 선택하도록 설정한다.
4.6 선택 평문 공격
- 보안이 허술하거나 악의적인 프락시가 트래픽 중간에 끼어든다면, 클라이언트가 응답 계산을 하기 위한 난스를 제공 할 수 있다.
- 응답을 계산하기 위해 알려진 키를 사용하는 것은 응답의 암호 해독을 쉽게 한다.
- 클라이언트가 서버에서 제공된 난스 대신 선택적인 c난스 지시자를 사용하여 응답을 생성할 수 있도록 설정하는 것이 좋다.
4.7 비밀번호 저장
- 다이제스트 인증 비밀번호 파일이 유출되면 영역의 모든 문서는 공격자에게 노출된다.
- 비밀번호 파일이 평문으로 된 비밀번호를 포함하고 있다고 생각하고 안전하게 보호한다.
- 영역 이름이 유일함을 보장한다.