


11장 클라이언트 식별과 쿠키
목표
서버가 통신하는 대상을 식별하는 데 사용하는 기술을 알아본다
1. 개별접촉
웹 서버는 요청을 보낸 사용자를 식별하거나 방문자가 보낸 연속적인 요청을 추적하기 위해 약간의 정보를 이용한다. 현대의 웹사이트 들은 개인화된 서비스를 제공하기 위해 여러가지 방식을 사용한다.
개별 인사
사용자에게 특화된 환영 메시지나 페이지 내용을 만든다
사용자 추천
고객의 흥미가 무엇인지 파악하고 고객에게 맞춤으로 제품을 추천한다
저장된 사용자 정보
온라인 쇼핑 고객은 주소와 신용카드 정보를 매번 입력하는 것을 싫어한다
온라인 쇼핑이 고객을 식별하고 나면 쇼핑을 더 편리하게 하도록 사용자 정보를 사용한다
세션 추적
HTTP 트랜잭션은 상태가 없어서 각 요청 및 응답은 독립적으로 일어난다
많은 웹사이트에서 사용자가 사이트와 상호작용 할 수 있게 남긴 사용자 정보를 유지하기 위한 HTTP 트랜잭션을 식별할 방법이 필요하다
2. HTTP 헤더
가장 일반적인 HTTP 요청 헤더 기술
From: 사용자의 이메일 주소User-Agent: 사용자의 브라우저Referer: 사용자가 현재 링크를 타고 온 근원 페이지Authorization: 사용자 이름과 비밀번호Client-ip: 클라이언트의 IP주소X-Forwarded-For: 클라이언트의 IP주소Cookie: 서버가 생성한 ID 라벨
3. 클라이언트 IP 주소
초기에는 사용자 식별에 클라이언트의 IP 주소를 사용하려고 하였다
확실한 IP 주소를 가지고 있고, 그 주소가 절대 바뀌지 않고, 웹 서버가 요청마다 클라이언트의 IP를 알 수 있다면, 문제가 되지 않는다
클라이언트 IP로 사용자를 식별한다면 많은 단점을 가지게 된다
- 만약 여러 사용자가 같은 컴퓨터를 사용한다면 그들을 식별할 수 없다
- 인터넷 서비스 제공자(ISP)는 사용자가 로그인하면 동적으로 IP 주소를 할당하기 때문에, 사용자는 매번 다른 주소를 받아, 웹 서버는 사용자를 IP 주소로 식별 할 수 없다
- 사용자들은 인터넷 사용시에 네트워크 주소 변환(Network Address Translation) 방화벽을 사용하는데, 방화벽은 사용자의 실제 IP를 숨기고 방화벽 IP 주소로 변환하므로 식별이 어렵다
- HTTP 프락시와 게이트웨이는 원 서버에 새로운 TCP 연결을 한다. 웹 서버는 클라이언트의 IP 주소 대신 프락시 서버의 IP 주소를 본다
4. 사용자 로그인
웹 서버는 사용자 이름과 비밀번호로 인증할 것을 요구해서 명시적으로 식별 요청할 수 있다
HTTP는 WWW-Authenticate와 Authorization 헤더를 사용해 웹 사이트에 사용자 이름을 전달하는 자체적인 체계를 가지고 있다.
1) 서버에서, 사용자가 사이트에 접근하기 전에 로그인을 시키고자 한다면 HTTP 401 ?Login Required 응답 코드를 브라우저에 보낼 수 있다.
2) 브라우저는 로그인 화면을 보여주고, 다음 요청부터 Authorization 헤더에 정보를 기술하여 보낸다.
5. 뚱뚱한 URL
웹 사이트는 사용자의 URL마다 버전을 기술하여 사용자를 식별하고 추적하기도 한다.
웹 서버는 URL에 있는 상태 정보를 유지하는 하이퍼링크를 동적으로 생성한다.
뚱뚱한 URL은 사이트를 브라우징 하는 사용자를 식별하는데 사용할 수 있지만, 여러 문제들을 가지고 있다.
- 브라우저 보이는 URL이 새로운 사용자들에게는 혼란을 준다.
- URl은 특정 사용자와 세션에 대한 상태 정보를 포함하므로, 해당 주소를 공유하게 된다면 개인정보를 공유하게 되는 것이다.
- URL로 만드는 것은 URL이 달라지기 때문에 기존 캐시에 접근할 수 없다는 것을 의미한다.
- 뚱뚱한 URL에 해당하는 HTML 페이지를 다시 그려야한다.
- 사용자가 특정 뚱뚱한 URL을 북마킹하지 않는 이상, 로그아웃하면 모든 정보를 잃는다.
6. 쿠키
사용자를 식별하고 세션을 유지하는 방식중에서 가장 널리 사용되는 방식이다.
쿠키는 매우 중요한 웹 기술이며, 새로운 HTTP 헤더를 정의한다.
6.1 쿠키의 타입
세션 쿠키(session cookie)와지속 쿠키(persistent cookie)타입으로 나뉜다.- 세션 쿠키는 사용자가 브라우저를 닫으면 삭제된다.
- 지속 쿠키는 디스크에 저장되어, 브라우저를 닫거나 컴퓨터를 재시작하더라도 남아있다.
6.2 쿠키는 어떻게 동작하는가
쿠키는 서버가 사용자에게 “안녕, 내 이름은…”라고 적어서 붙이는 스티커와 같다.
웹 서버는 사용자를 식별하기 위해 임의의 이름=값 형태로 쿠키에 할당한다.
할당된 리스트는 Set-Cookie 또는 Set-Cookie2 같은 HTTP 응답 헤더에 기술되어 사용자에게 전달한다.
6.3 쿠키 상자: 클라이언트 측 상태
쿠키는 브라우저가 서버 관련 정보를 저장하고, 사용자가 해당 서버에 접근할 때마다 그 정보를 함께 전송하는 것이다.
브라우저는 쿠키 정보를 저장할 책임이 있는데, 이 시스템을 클라이언트 측 상태라고 한다.
6.4 사이트마다 각기 다른 쿠키들
브라우저는 쿠키 전부를 모든 사이에 보내지 않고, 보통 두세 개의 쿠키만을 보낸다. 이유는 다음과 같다.
- 쿠키를 모두 전달하면 성능이 크게 저하된다.
- 대부분 서버에 특화된 이름/값 쌍을 이루므로, 대부분 사이트에서는 인식하지 않는 무의미한 값이다.
- 특정 사이트에서 제공한 정보를 신뢰하지 않는 사이트에 가지고 갈 수 있으므로 잠재적인 개인정보 문제를 일으킬 수 있다.
6.5 쿠키 구성요소
현재 사용되는 쿠키로 Version 0(넷스케이프 쿠키)과 Version 1(RFC 2965) 쿠키가 존재한다.
Version 0(넷스케이프 쿠키)
최초의 쿠키 명세
Set-Cookie: name=value [;expires=date] [;path=path] [;domain=domain] [;secure]
Cookie: name1=value1 [;name2=value2]…
Version 1 (RFC 2965) 쿠키
쿠키의 확장 버전으로 Version 0 시스템과도 호환된다.
넷스케이프 버전보다 복잡하며, 아직 모든 브라우저나 서버가 완전히 지원하지 않는다.
주요 변경사항
- 쿠키마다 그 목적을 설명하는 설명문이 있다.
- 쿠키의 생명주기를 결정할 수 있다(Max-Age)
- URL의 포트번호로도 쿠키를 제어할 수 있다.
- 브라우저가 닫히면 쿠키를 강제로 삭제할 수 있다.
6.6 쿠키와 세션 추적
쿠키는 웹 사이트에 수차례 트랜잭션을 만들어내는 사용자를 추적하는 데 사용한다.
Amazon.com 사이트에 방문하면 일어나는 트랜잭션의 연속을 알아본다.

- a) 브라우저가 Amazon.com 페이지를 처음 요청한다.
- b) 서버는 클라이언트를 전자상거래 소프트웨어 URL로 리다이렉트 시킨다.
- c) 클라이언트는 리다이렉트 URL로 요청 보낸다.
- d) 서버는 응답에 두 개의 세션 쿠키를 기술하고 사용자를 다른 URL로 리다이렉트 시키며, 클라이언트는 다시 이 쿠키들을 첨부하여 요청을 보낸다.
- e) 클라이언트는 새로운 URL을 요청을 팡서 받은 두 개의 쿠키와 함께 보낸다.
- f) 서버는 home.html 페이지로 리다이렉트 시키고 쿠키 두 개를 더 첨부한다.
- g) 클라이언트는 home.html 페이지를 가져오고 총 네 개의 쿠키를 전달한다.
- h) 서버는 콘텐츠를 보낸다.
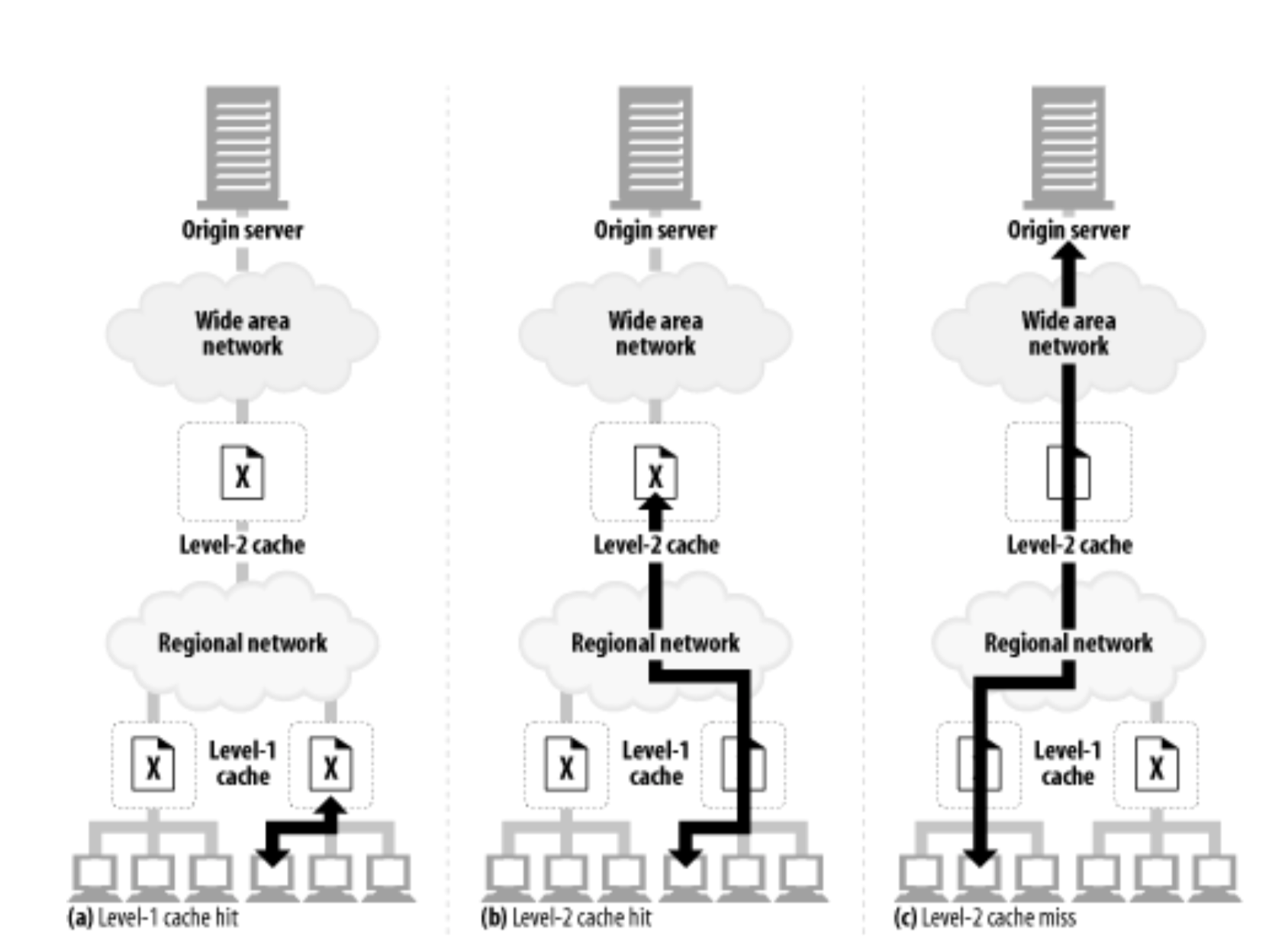
6.7 쿠키와 캐싱
쿠키 트랜잭션과 관련된 문서를 캐싱하는 것은 주의해야 한다.
이전 사용자의 쿠키가 다른 사용자에게 할당되어 누군가의 개인정보가 유출될 수 있다.
캐시를 다루는 기본 원칙
캐시되지 말아야 할 문서가 있다면 표시하라
- 문서가 Set-Cookie 헤더를 제외하고 캐시를 해도 될 경우라면
Cache-Control: no-cache="Set-Cookie"를 명시적으로 기술한다.
Set-Cookie 헤더를 캐시하는 것에 유의하라
- 같은 Set-Cookie 헤더를 여러 사용자에게 보내게 되면, 사용자 추적을 실패하게 된다.
- 원 서버는
Cache-Control: must-revalidate, max-age=0헤더를 캐시된 문서에 추가함으로써 재검사가 일어나게 할 수 있다.
Cooke 헤더를 가지고 있는 요청을 주의하라
- 요청이 Cookie 헤더와 함께 오면, 결과 콘텐츠가 개인정보를 담고 있을 수도 있다는 힌트이다.
- Set-Cookie가 있는 이미지에 대해서는 캐시를 하지만 Set-Cookie가 있는 텍스트는 캐시를 하지 않는 캐시도 있다.
- 캐시 이미지에 파기 시간이 0인 Cookie 헤더를 설정해서 매번 재검사를 하도록 강제한다.